Medical Devices and Materials Engineering SectionHuman Centric Information Processing
High Quality Speech Synthesis with Emotion and Speaker Individuality by DNN
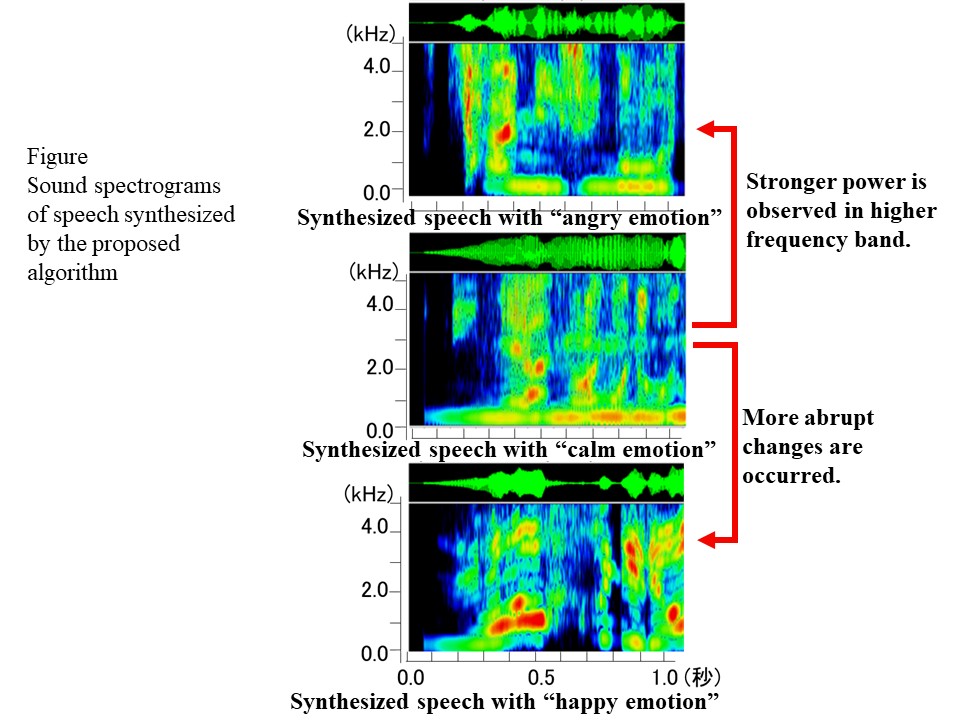
Although the intelligibility and naturalness of synthetic speech have been greatly improved, its quality is not satisfied in terms of emotional expressions. To solve the problem, we propose a new algorithm for generating Speech-like Emotional Sound (SES) using WaveNet as a sound generator. The proposed algorithm consists of two steps. In the first step, WaveNet is trained to obtain phonetic features using a large speech database, and in the second step, WaveNet is re-trained using a small amount of emotional speech. The biggest advantage of the idea is to reduce the amount of emotional speech data for the training. Subjective listening evaluations showed that the SES could convey emotional information and was judged to sound like a human voice.
Introduction of Researchers
Medical Devices and Materials Engineering Section Human Centric Information Processing